新北垃圾收運小幫手:完整RAG架構助力市政服務數位轉型
 2026/01/29
2026/01/29
背景概述
隨著生成式 AI 的普及,打造一個會說話的 Chatbot 已非難事,但要將其應用於容錯率極低、資訊高度動態的市政服務,則面臨著嚴峻的工程挑戰。如何確保AI不會因「幻覺(Hallucination)」而誤報法規資訊?如何讓龐雜的非結構化數據實現即時更新?這些都是一般通用模型無法解決的痛點。
信諾科技憑藉在 AI 落地應用與數據治理的深厚積累,不僅止步於創意的發想,更專注於底層架構的打磨。信諾團隊在與新北市環保局合作的「新北垃圾收運小幫手」AI客服中,構建了一套結合 NLP 、自動化 ETL 與 HNSW 的 RAG 架構。本文將深入揭密這套系統背後,工程師是如何透過數據工程,將傳統的關鍵字查詢,轉化為直觀且可信賴的智慧服務。
架構深度解析:驅動高信賴 AI 的進階 RAG 工程
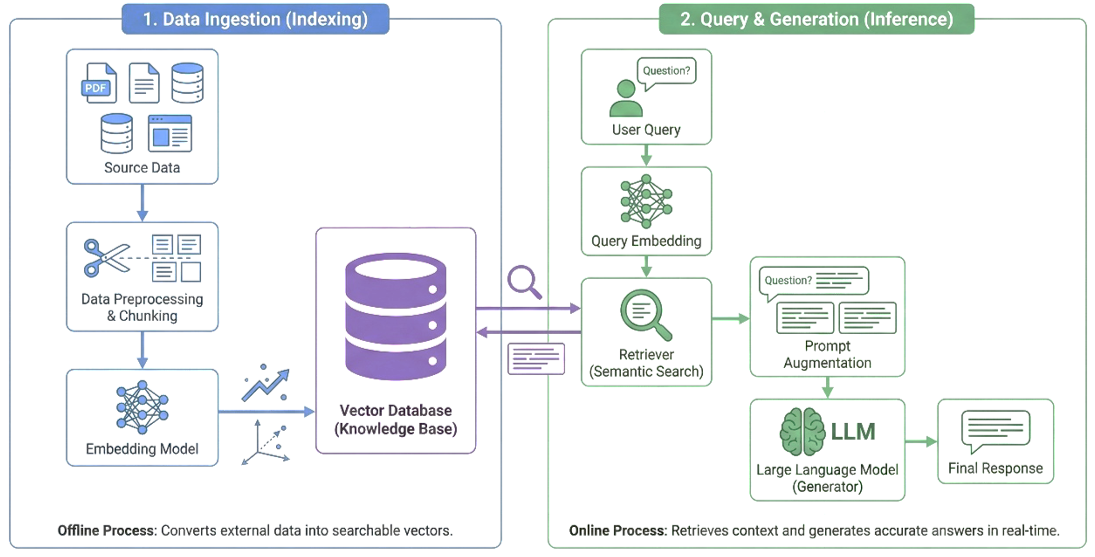 ▲RAG架構示意圖(圖表由本團隊製作)
▲RAG架構示意圖(圖表由本團隊製作)
RAG(檢索增強生成)技術是目前解決 AI 幻覺最有效的路徑,其核心原理在於「先檢索、再生成」,讓 AI 有憑有據地回答問題。面對市政服務「高準確度、高動態性」的嚴苛要求,信諾科技構建了一套整合 NLP 語意分析、自動化 ETL 資料管線 以及 HNSW 高速向量演算法的 RAG 架構。這三大技術支柱分別解決了「意圖識別」、「資料管理」與「高速檢索」的關鍵難題,將非結構化的市政數據轉化為快速、準確的智慧服務。
一、智慧中樞:自然語言處理 (NLP) 與意圖識別
系統的核心並非單純的關鍵字匹配,而是建立在GPT模型強大的自然語言處理 (NLP) 能力之上。當使用者輸入模糊的口語問題時,系統能透過 GPT Function Calling (函式呼叫),將非結構化的語句拆解為「人、事、時、地、物」等結構化參數。接著,系統進行意圖識別,依據參數屬性進行智慧分流,將問題分為即時型(清運站資訊)與知識型(法規、回收知識等)兩種。若涉及定點清運,系統會利用拆解出的「地點/時間」參數,直接對接環保局的垃圾車班表數據 API,獲取清運時間表並給出對應資訊;若涉及法規或回收知識,則導向後端的 RAG 向量檢索流程。
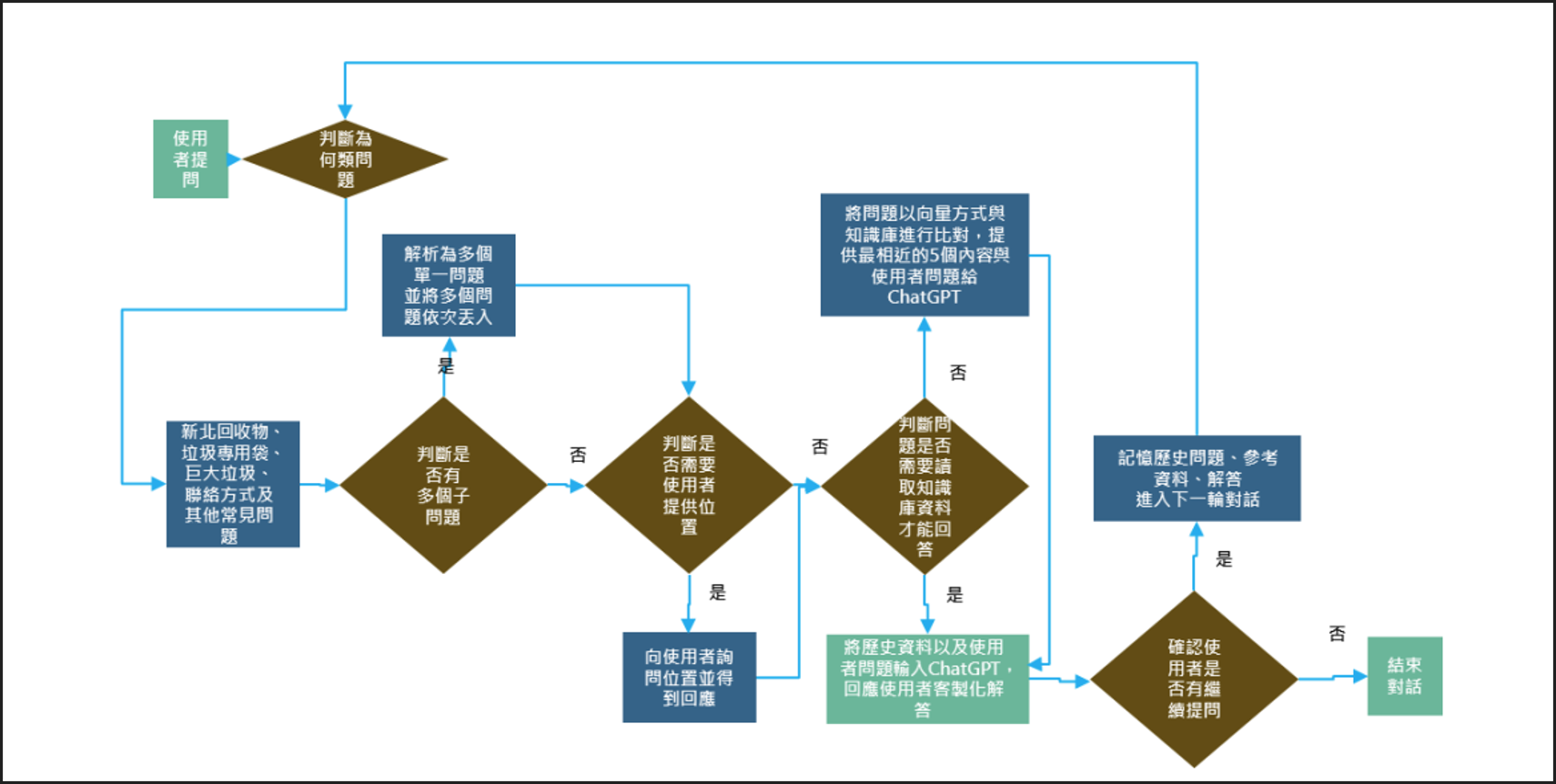 ▲分流後知識型問題判斷流程
▲分流後知識型問題判斷流程
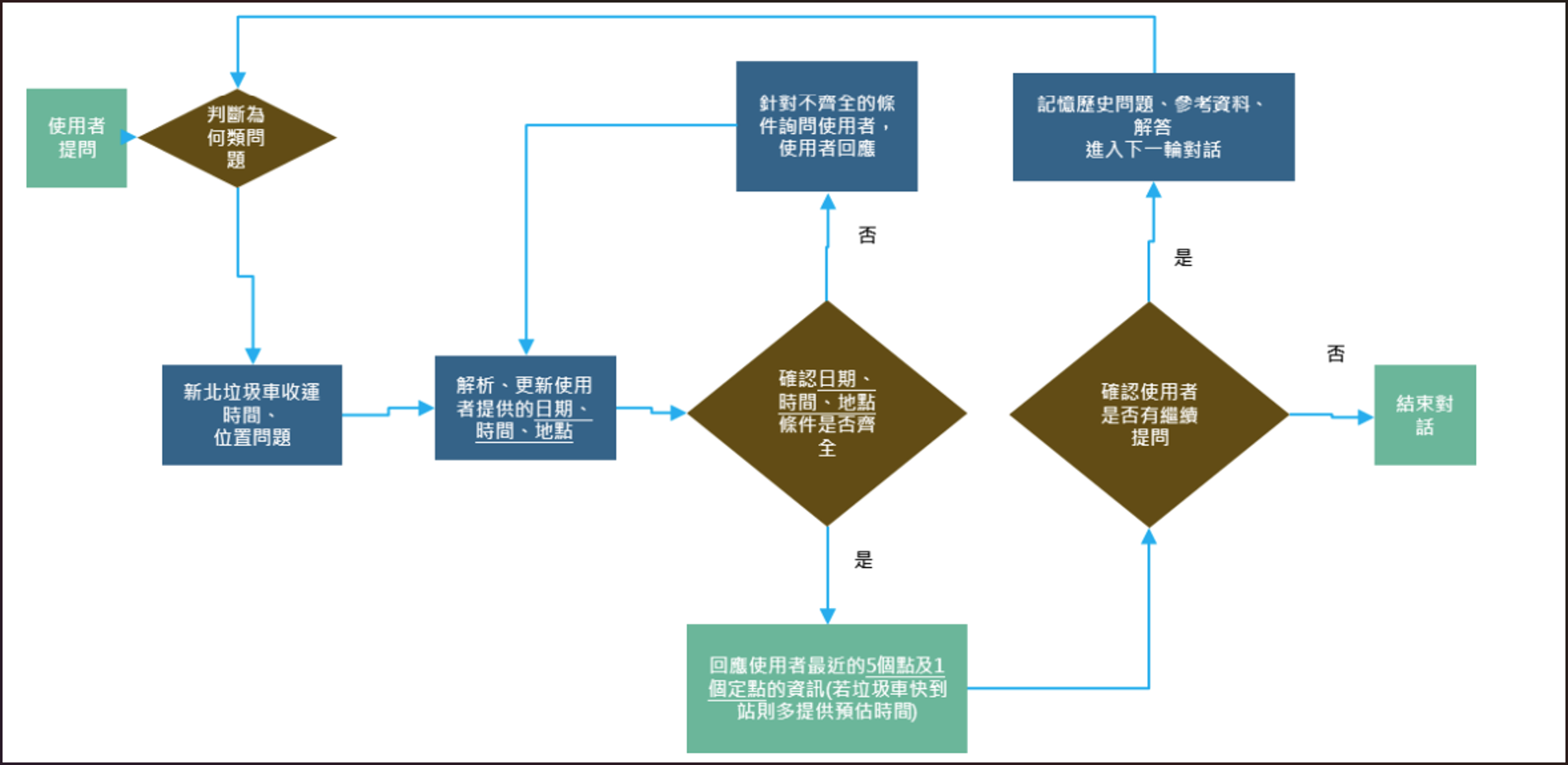 ▲分流後即時型問題判斷流程
▲分流後即時型問題判斷流程
二、資料管線(Data Pipeline):異質資料清洗與增量更新
AI的準確度取決於數據的純淨度。針對來源紛雜的市政資料(如爬蟲網頁抓取的 HTML 資料、環保局提供之 Excel、PDF 檔案等),信諾構建了一套嚴謹的 ETL (Extract, Transform, Load) 流程,確保資料庫的純淨與即時性。
- 資料清洗:
在資料進入切片環節前,原始檔案會先經過系統的自動化清洗流程,剔除無意義的雜訊(如 Excel 標題列、重複標點、HTML 標籤等),確保進入模型的每一份數據皆為有效資訊。
- 資料切片:
鑑於原始資料格式、內容大多零碎,團隊不採用傳統的句子切片 (Sentence-based Chunking) 或是語意切片 (Semantic Chunking),而是導入摘要式索引策略 (Summary-based Indexing)。利用LLM針對每一筆資料進行語意重組,生成摘要 (Summary) 或問答對 (QA Pairs),確保即使原始資料格式雜亂,檢索系統仍能精準鎖定最具代表性的語意核心。處理完成後,資料存入MongoDB文字資料庫進行保存,並使用 GPT 嵌入模型將這些結構化文本進行向量化處理,存入 Qdrant 向量資料庫,便於系統檢索。
 ▲資料經由切片後儲存於MongoDB文字資料庫中
▲資料經由切片後儲存於MongoDB文字資料庫中
- 增量更新機制 (Incremental Update):
若有新資料需要更新,在存入 MongoDB 文字資料庫並開始進行資料清洗前,系統會基於 Metadata 進行鍵值比對 (Key-Value Check),自動計算新舊資料差異,僅針對變動部分進行增量更新或覆蓋,降低運算成本並確保資料時效。同時,資料庫也支援手動添加資料,譬如前段時間,非洲豬瘟影響居家廚餘的處理形式,團隊便將相關資訊導入資料庫,確保資料庫回答的合規性及時效性。
三、 快速檢索與生成:HNSW 演算法與動態渲染
為了在海量數據中實現快速回應,信諾在檢索層與表現層導入高效的演算法與渲染技術。
- HNSW 向量檢索:
在 Qdrant 向量資料庫中, 使用HNSW (Hierarchical Navigable Small World) 演算法能發揮出最快、最好的檢索品質。利用此演算法時,首先會先在多維向量空間中的最上層進行大範圍的跳躍,在大量向量資訊中迅速鎖定相似目標區域;下層結構則負責精細的局部搜索,相比起一般的暴力搜索,在維持精度的情況下,速度更快,可以僅針對相似目標進行搜索,避免了傳統暴力檢索需比對全量數據的效能瓶頸。小幫手在 HNSW 的幫助下,便可以進行毫秒級的搜索,有助於更快提供精確資訊,提高使用體驗。
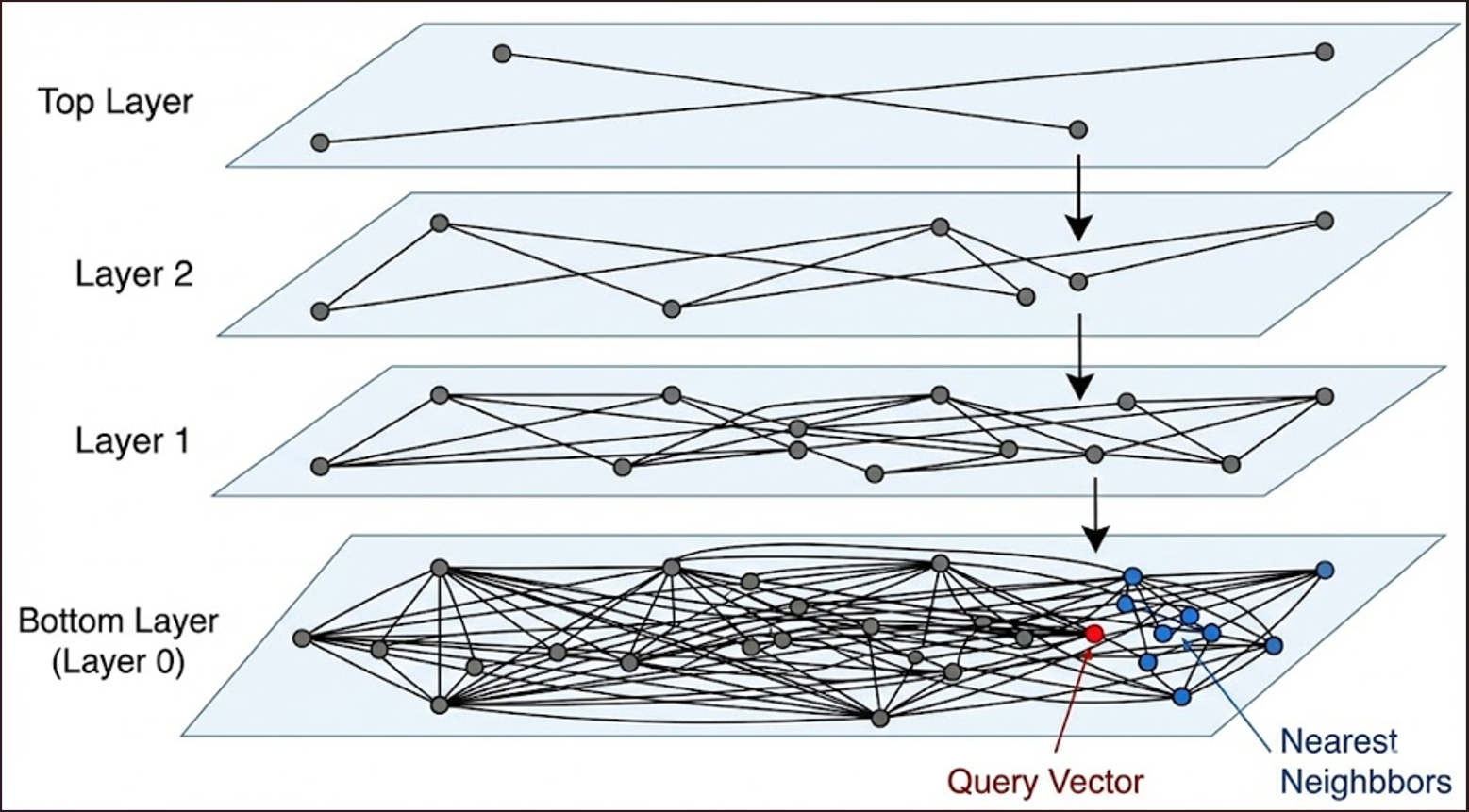 ▲HNSW演算法示意圖(圖表由本團隊製作)
▲HNSW演算法示意圖(圖表由本團隊製作)
- 上下文組裝 (Context Assembly):
系統會依照餘弦相似度 (Cosine Similarity) 計算出的分數,篩選並排序相似度最高的前5筆相關資訊作為上下文,投餵給大語言模型進行處理並執行自然語言生成 (NLG),給出解答。
- 前端動態渲染 (Adaptive Rendering):
在進行回答時,前台介面會根據分軌類型進行差異化呈現,確保最佳的閱讀體驗與資訊正確性:
- 即時型資訊(如清運班表):
前台將後端回傳的結構化數據,封裝進預先設計好的 UI (Card Design),直觀呈現時間、地點,點擊清運點卡片後也可一鍵直達官網中的對應清運點資訊列,透過資訊列中的 Google Maps連結導航至該清運點。
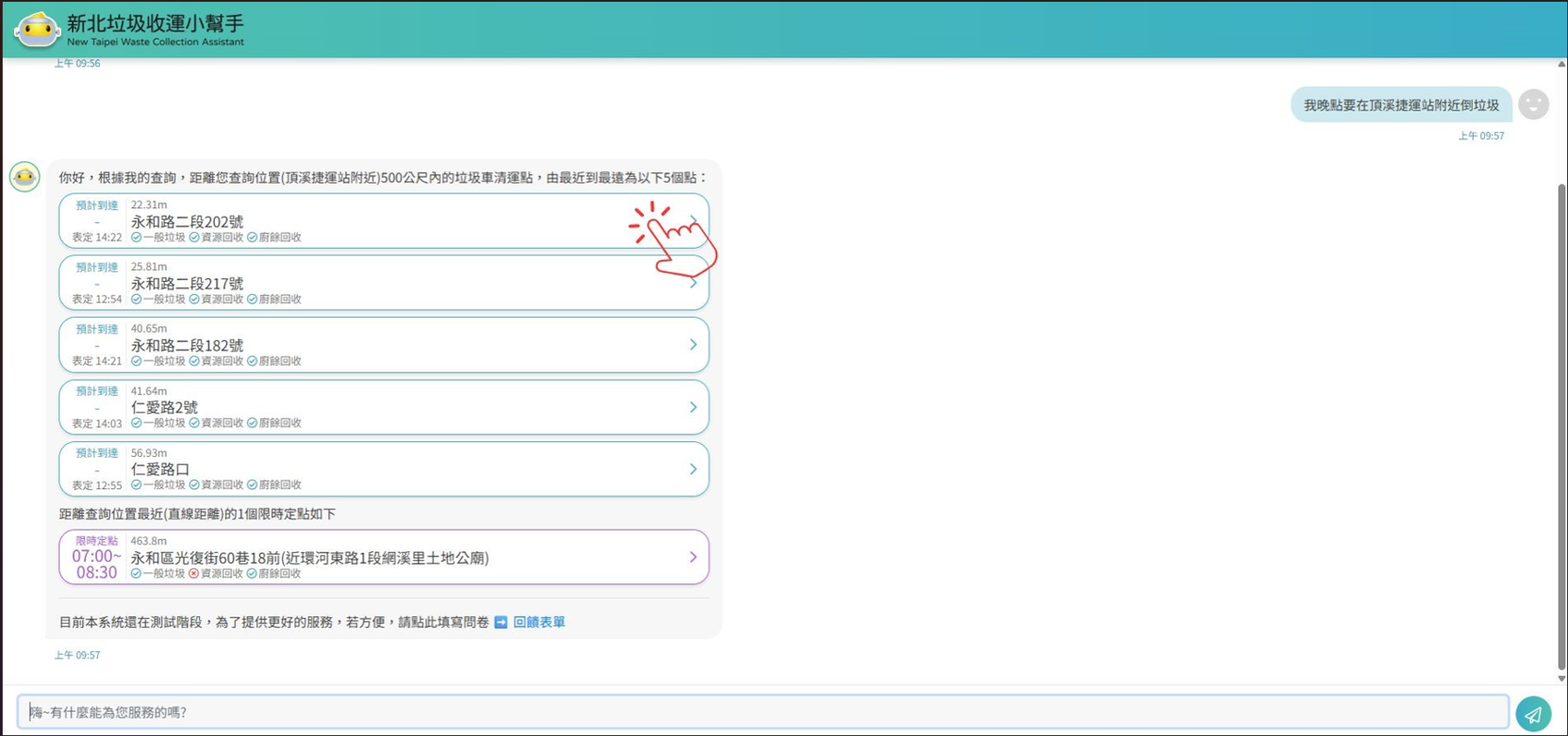 ▲藉由前端 UI,使用者透過點擊資訊卡即可查看該站點詳細資料
▲藉由前端 UI,使用者透過點擊資訊卡即可查看該站點詳細資料
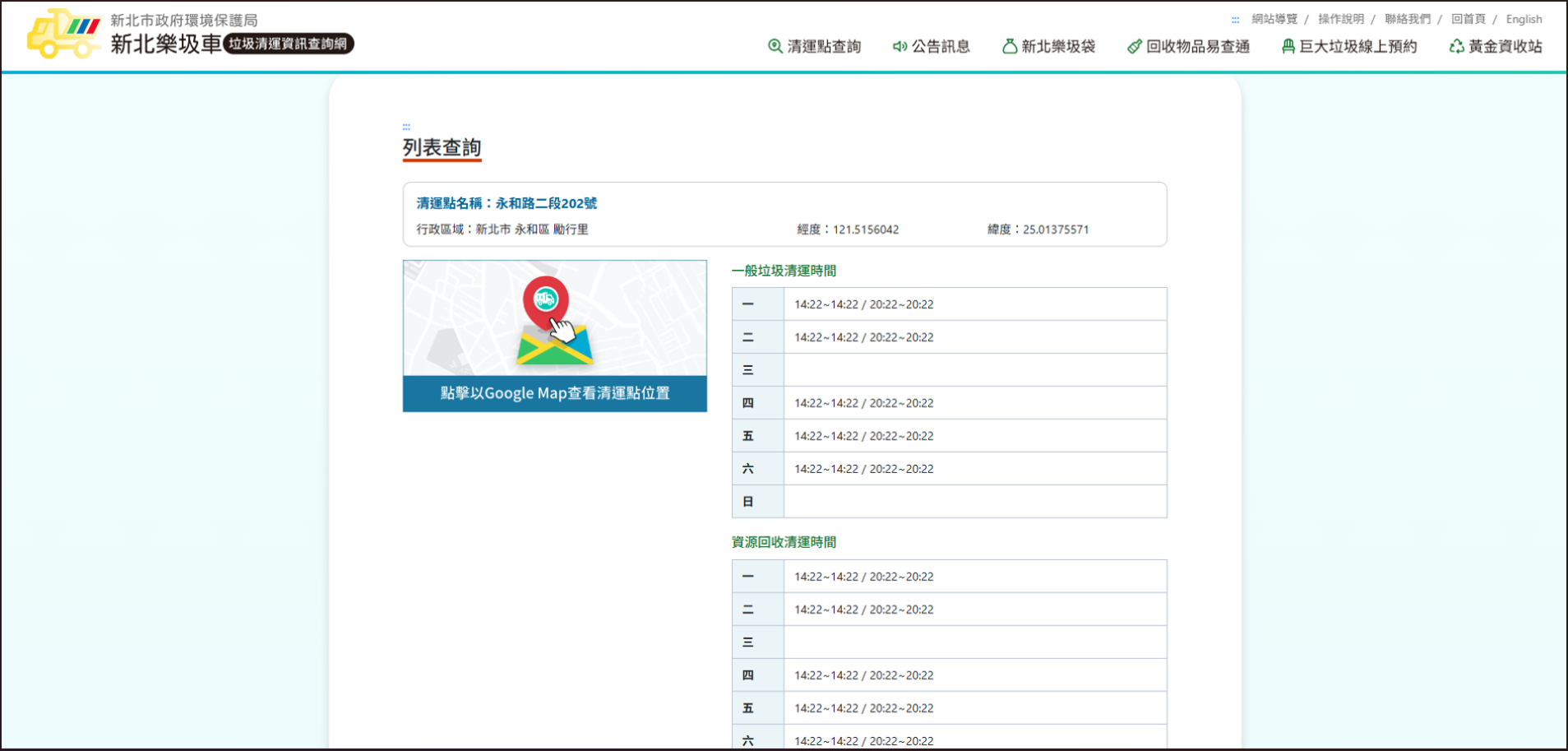 ▲進入官網後可進一步點擊 Google Maps直接導航該站座標
▲進入官網後可進一步點擊 Google Maps直接導航該站座標
- 知識型資訊與網址審核:
若為知識型相關問題,則上方顯示LLM生成的精準解答,下方自動列出相關網址供使用者點閱求證。為了確保資安,提供的網址皆受嚴格的「白名單機制」管控,若偵測到不明或非白名單內的連結將自動濾除,杜絕釣魚網站或幻覺編造無效連結的風險,確保市民的每一次點擊都安全無虞。此外,系統掛載「查詢結果僅適用於新北市境內」的警示標語,嚴謹界定資訊適用範圍。
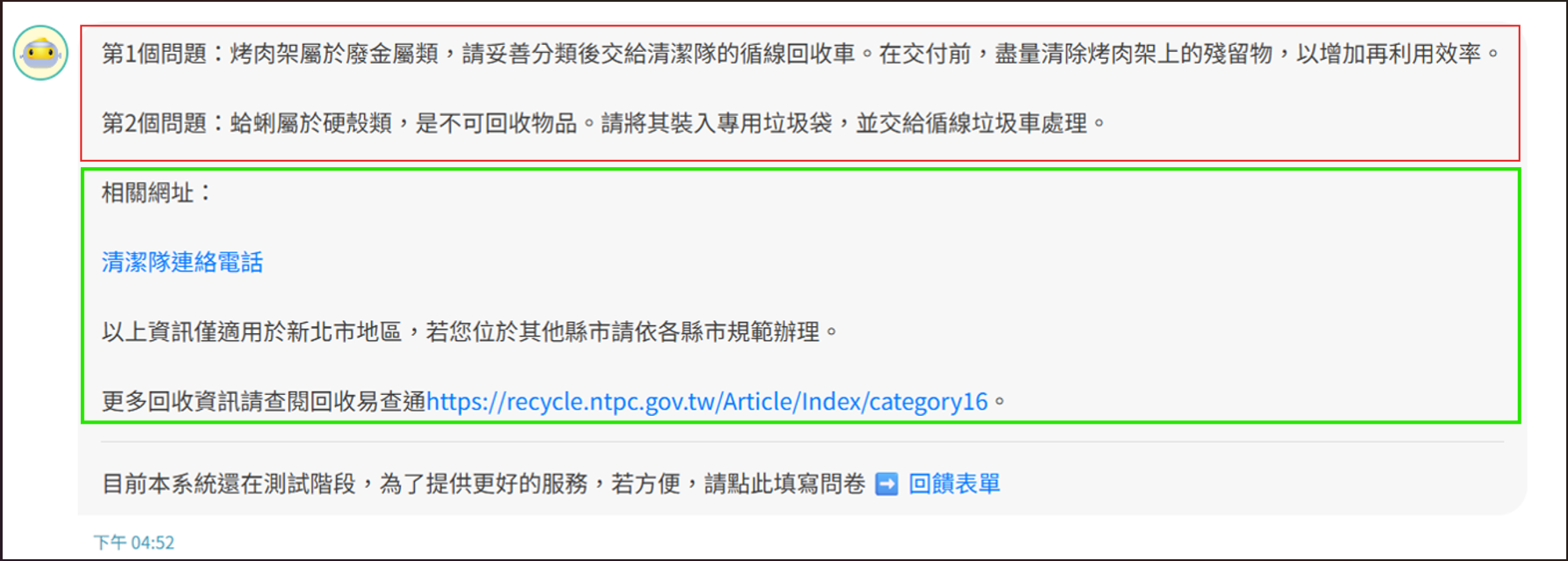 ▲上方(紅框)為LLM回覆,下方(綠框)列出相關網址方便使用者查詢點閱
▲上方(紅框)為LLM回覆,下方(綠框)列出相關網址方便使用者查詢點閱
結語:以紮實技術底蘊實現智慧治理,驅動市政服務數位轉型
「新北垃圾收運小幫手」的流暢體驗,是無數工程細節堆疊而成的成果。從底層的 ETL 資料清洗、中層的 HNSW 向量檢索演算法,到上層的意圖識別與適應性渲染,信諾解決傳統 LLM 應用中常見的幻覺與延遲問題,將先進技術融入市政服務。
透過這套紮實的 RAG 架構,信諾實現市政服務的數位轉型,更為擴展更多元的 AI 應用場景打下堅實基礎。未來,信諾科技將在 AI 落地應用的道路上持續深耕,為台灣社會提供安全與效益兼具的數位解決方案。
產業分類
性質分類
關鍵字
RAG 檢索增強生成 HNSW NLP 意圖識別 自動化 ETL 數位轉型 市政服務 AI 精準治理 智慧城市 大數據應用
回上一頁